4. Machine Learning ABC
In machine learning, variables are often split into feature variables and target variables. Feature variables are the inputs to the model—information that helps the model make predictions—while target variables are the outcomes or labels the model is intended to predict. For instance, in the case of handwritten digit recognition, each pixel value in the image of a digit acts as a feature, providing the model with clues about the visual patterns, while the digit number itself (such as “5” or “9”) is the target variable. Similarly, in medical imaging applications like pseudo-CT imaging, the pixel values from an MRI image may serve as features, and the corresponding CT image’s pixel values become the target, as the model aims to predict CT values based on MRI inputs. There are many ways to categorize machine learning, with the most common being supervised and unsupervised learning. This categorization primarily depends on whether target variables are included in the research problem.
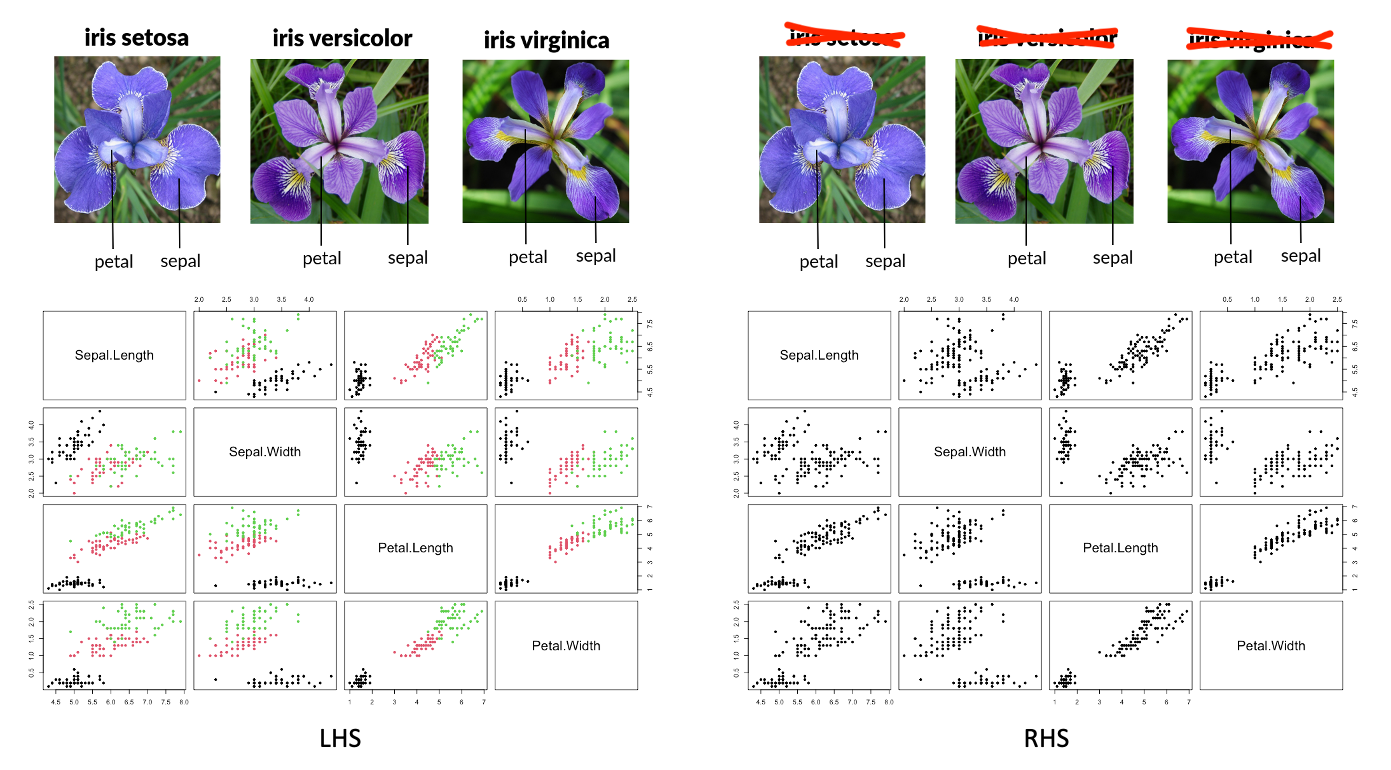
In supervised learning, a dataset includes known labels for each observations, which the model uses to learn relationships between features and targets. In a mathematical language, we try to find a map \(f\), or a function, that connect the features information and target information. For example, the Iris dataset is labeled with flower species (such as Setosa or Versicolor) based on measurements like petal length and width, which act as feature variables. The goal is for the model to learn these relationships so it can classify new, unseen examples accurately. This mapping, \(f\), also known as the model, has its functionality determined by model parameters, which are adjusted based on the data. The process of determining the “optimal” parameters is also called to ‘learning’. Once the optimal model parameters are set, the model is considered trained. In the case of the Iris example, for those who often confuse the three subspecies, the shape data of the flower can be used to predict the species. Many plant identification Apps work in this way. Supervised learning is often further divided into regression and classification problems, depending on the type of target variable. We will focus on this distinction in the following section.
In unsupervised learning, on the other hand, the dataset has no target variables, and the model’s task is to find underlying patterns or groupings in the data, such as clustering the Iris dataset’s measurements into groups without knowing the species in advance. In mathematical language, in unsupervised learning problem, we also want to learn a map \(g\) that connect feature variables and some “new” knowledge. In statistics, we often use the term “latent variable” or “latent information” to represent this “new” knowledge. The beautiful names Setosa, Versicolor, and Virginica did not exist before botanists classified and named them scientifically. This new knowledge emerged from analyzing data on the shapes of the flowers. In machine learning, we typically encounter two types of unsupervised learning problems: feature analysis and cluster analysis. In the first part of this course, we will not cover these topics.
Quiz: In fact, we have encountered similar unsupervised learning problems in basic statistics. Do you know what they are?