2. Philosophy of Machine Learning
Let’s first discuss some metaphysical matters. What is the philosophy behind machine learning? Let’s begin with the story about handwritten digit data. In the past, postal workers had to manually sort all mails according to handwritten post code. Aside from the high labor costs, we all would consider this an extremely tedious job with a high error rate. So, people wondered if they could scan handwritten post codes into computer and then let the computer recognize the digits. This is how handwritten digit data came into existence.
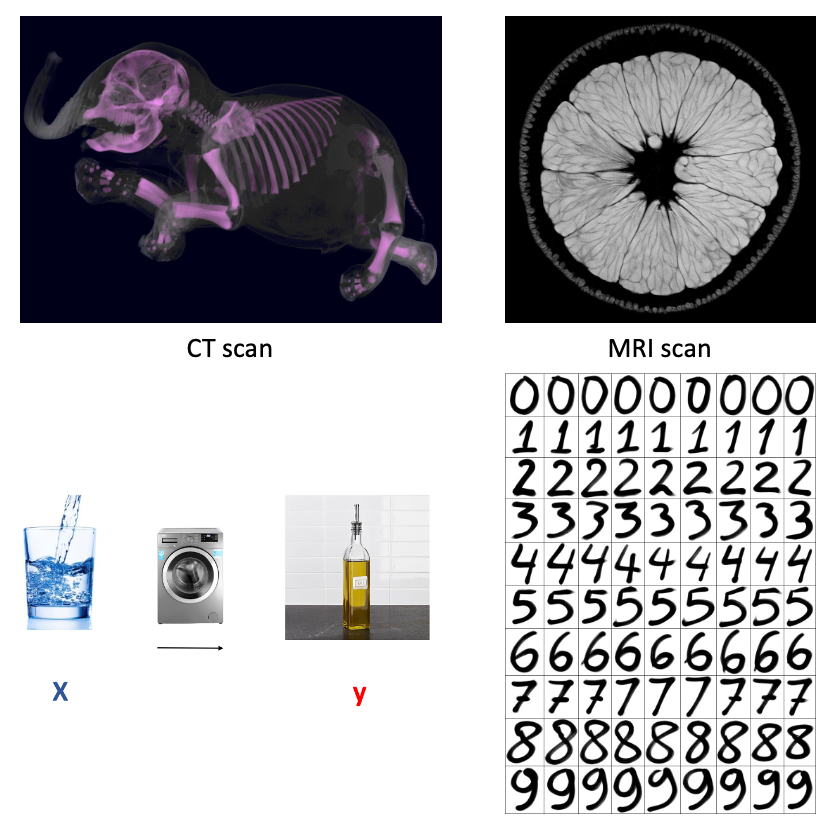
Another story is about medical imaging. In recent years, hospitals have introduced MRI technology for medical imaging. MRI excels in presenting soft tissue, and its use of magnetic fields results in minimal harm to the body. In contrast, traditional CT imaging relies on X-rays, which can have noticeable side effects on the human body. However, CT imaging is irreplaceable when it comes to displaying the solid tissues, like skeletal structure. Therefore, people have contemplated whether it’s possible to generate corresponding CT images from MRI image data, giving rise to the concept of generative CT images.
The two examples have a common feature, that is we aim to predict ‘expensive’ information using ‘cheap’ information. In the story of post office, the “cheap” information is the easily obtained image data, while the recognition of the postal code is considered “expensive” information. In the medical imaging story, the acquisition of MRI image data carries far less risk compared to the risks associated with CT images. From this perspective, MRI data is indeed much more cost-effective than CT data. Therefore, the basic idea of machine learning is to train a “machine” to transform “cheap” information into “expensive” information through data. In this way, expensive information is replaced by cheap information through machine learning models, thus avoiding high costs, unnecessary error costs, and additional risks.