4. Deep Learning
I feel very lucky because we have witnessed a significant historical phase in humanity together. I remember in 2016, I was sitting on bus line 8 in Umeå, watching the live broadcast of the match between the Korean Go player Lee Sedol and AlphaGo on my phone. I was very conflicted at that time. First, I had always been proud of my ancestors for inventing Go (Weiqi), and I didn’t want the final intellectual barrier created by them to be easily overcome by computers. At the same time, I was very interested in the development of machine learning and was eager to see humanity make breakthroughs in the field of artificial intelligence. However, that spring, on the bus, I witnessed the singularity of human development. As a result, AlphaGo defeated Lee Sedol 4-1. Therefore, I am willing to regard the event of AlphaGo, based on deep learning, defeating top human Go players as a major milestone in the field of artificial intelligence.
Remark: It is worth mentioning that the Go player Lee Sedol, who was facing off against AlphaGo, was about to retire and was not considered the number one player in Go at that time. I guess, if the match had been played by the Chinese player Ke Jie, we would have to push this milestone further back. However, when Ke Jie competed a year later, AlphaGo had already evolved into the unbeatable AlphaGo Zero.
4.1 Retrospect

Although we have not yet introduced another famous machine learning model, the Support Vector Machine (SVM), we will use it as a reference to review the history of ANN and deep learning in the development of machine learning. Therefore, I will briefly introduce the characteristics of SVM here. SVM is a nonlinear machine learning model that belongs to the kernel methods family. It primarily uses the concept of feature mapping to nonlinearize a linear model. However, its approach to feature mapping is quite unique. Instead of manually selecting an appropriate feature mapping to get the augmented feature space, SVM employs a mathematical tool called the kernel function to control the final augmented feature space, allowing for a more flexible use of an unknown feature mapping through hyperparameters. (Note: Later, we will encounter the term “kernel” again in convolutional neural networks, but these are entirely different concepts.) Due to the use of kernel functions, along with convex optimization and the concept of reproducing kernel Hilbert space, SVM has gained a strong and solid theoretical foundation. Its flexibility and relatively low data requirements once made SVM the dominant model in the field of machine learning. Even today, you can still find many studies and explorations of deep learning through the perspective of kernel functions. I have a set of quite good notes for learning SVM and kernel methods. I will write them up and publish them on Yggdrasil later. If you’re interested, stay tuned! 😊
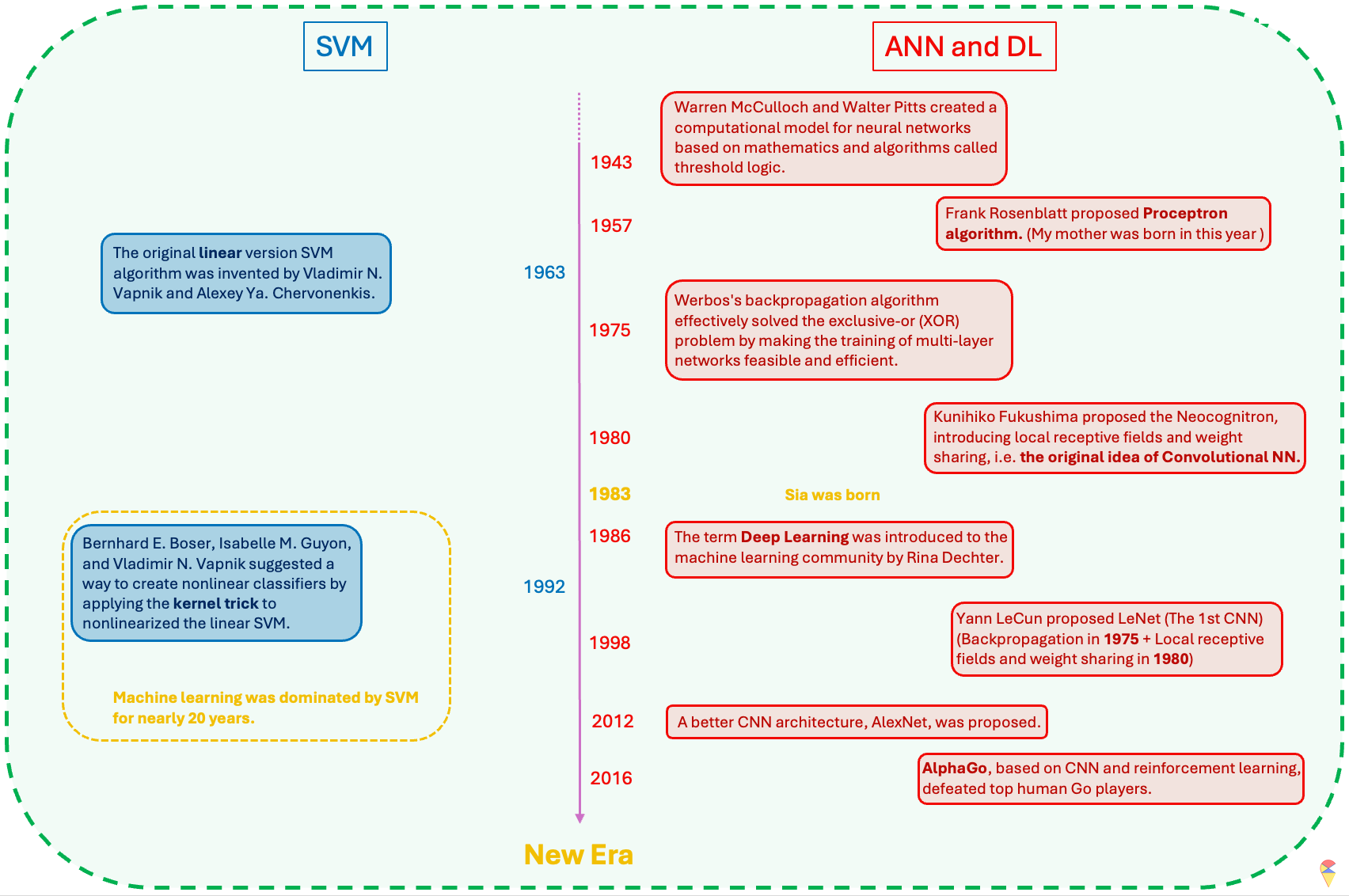
I have summarized the historical review of the field of machine learning in the image above. After reading it, you will realize that ANN is actually a very old concept and idea. The reason why machine learning was not as popular as it is today and was dominated by SVM for 20 years was mainly that the timing was not right—the two most critical factors had not yet matured.
So, what are those two key factors? The first key factor is data. There is an old Chinese saying, “A clever housewife cannot cook without rice.” Indeed, in the era before the internet and digital technology advanced, it was difficult to obtain high-quality data. The number of parameters in neural network models is often staggering, and insufficient data can directly lead to overfitting or even prevent the neural network model from being trained at all. Secondly, computational power is also crucial. Our small smartphones today are much more powerful than the computers of the past. The computational requirements for neural network models and their gradient information are enormous, so this critical factor is not hard to understand. However, the new era has arrived! We now have a much better kitchen now. It’s not just the “clever housewives” anymore—now, everyone can step into the kitchen and cook!

4.2 From Shallow to Deep
Before the success of deep learning, research in the field of machine learning on neural networks was primarily limited to shallow neural network models. These models typically had fewer layers, often just one hidden layer, and were more limited in their ability to capture complex patterns and representations in data. Deep learning specifically refers to machine learning models that utilize deep neural networks, which are neural networks with many layers. These models are capable of learning complex representations of data by processing it through multiple levels of abstraction, hence the term “deep.” So, when you refer to deep learning, it typically involves using deep neural network architectures for tasks such as image recognition, natural language processing, and speech recognition.
Shallow ANN:
Easier to train, more efficient:
Shallow ANN model typically consist of fewer layers and are simpler in structure, which makes them easier and faster to train. With fewer parameters to optimize, the training process is often more efficient and less computationally expensive compared to deeper models.Simpler decision structure:
The decision-making process in shallow ANNs is relatively straightforward. Since the networks have fewer layers, the information flow is less complex, which can sometimes lead to easier interpretability. However, this simplicity limits their ability to model more intricate patterns and relationships within data.Good enough theory:
Theoretical foundations for shallow ANNs are well established and understood. These models work well in many classical machine learning tasks where data is not overly complex. Shallow networks can perform well with simpler datasets, and the theory behind them has been solid for decades.
Deep ANN:
‘Arbitrarily’ powerful:
Deep ANNs are composed of many layers, each learning more complex patterns. This feature have the theoretical potential to model virtually any function and capture highly non-linear relationships in data.More ‘meaningful’ feature extraction:
As the End to End learning method, one of the major advantages of deep networks is their ability to learn hierarchical features in different levels automatically. This ability to perform automatic feature extraction is crucial in fields like computer vision, natural language processing, and speech recognition.More challenges:
Deep networks come with significant challenges. However, apart from lacking a solid theoretical foundation, researchers in the field of deep learning have essentially overcome various challenges. Next, let’s discuss the various solutions that deep learning has developed to face its challenges.
4.3 Challenges and Solutions
Challenge 1: High complexity model. Deep learning models based on deep neural network architectures have a considerable number of model parameters. This means we need to train models with high complexity. When the data volume is insufficient, overcoming the overfitting problem becomes our first challenge. People have approached this problem from both the model and data aspects.
First, in terms of the model, various regularization techniques have been introduced. For example, adding an L2 penalty to the neuron activation function, and introducing practical methods such as dropout learning and early stopping during model training. These methods are easy to understand. I suggest you read textbook sections 10.7.2 to 10.7.4 (pages 436-439).
Secondly, in situations where data is insufficient, many methods have also been proposed to overcome this challenge. For example, data augmentation is a very straightforward method.
In the previous section, we mentioned that the initial values of model parameters are crucial when training a model. A good set of initial values can help us find the optimal model parameters more quickly and avoid getting trapped in local optima. Therefore, based on this idea, concepts such as pre-training, fine-tuning, and transfer learning have also been proposed.
About Pre-training:
In many cases, the size of the dataset itself is substantial, but due to various reasons, the amount of annotated data is limited. In such situations, we can consider pre-training. The general idea is to first train an unsupervised learning model, such as an autoencoder, using a large amount of data. Then, we retain all pre-trained results from the encoder part and connect it to the target variable, forming a neural network model. Finally, we train the neural network model using the pre-trained parameters as initial values.
It is generally believed that, although pre-training lacks the guidance of the target variable, the learned model parameters still hold some significance. Therefore, they can be considered relatively close to the ideal model parameters.
About Pre-trained Model and Transfer Learning: These two strategies have become increasingly popular. A Pre-trained Model refers to a neural network model trained on a large annotated dataset, which is then applied to a smaller annotated dataset with the same model architecture. It is believed that using the parameters of a pre-trained model as the initial values for an optimization algorithm allows for training a better model with less annotated data. This training process is also known as fine-tuning. Fine-tuning is often achieved with the help of freezing. Simply put, this means fixing the parameters of certain layers in the neural network and only training the unfrozen layers using a limited amount of annotated data.
A broader concept is transfer learning, which is inspired by human behavior. We often assume that if a person is skilled at playing one musical instrument, they can quickly learn another. The same principle can be applied to deep learning. For example, recognizing digits and recognizing letters are very similar tasks. Suppose we have a large amount of labeled digit images but only a small amount of labeled letter images. In this case, we can first train a pre-trained model on digit images and then fine-tune it on letter images.
A more extreme approach would be to use the digit-trained model as a feature extractor for letter images, obtaining high-quality feature representations. These extracted features can then be used, along with labeled letter images, to train a separate machine learning model.
![]()
Challenge 2: More tricky optimization problems. We have previously mentioned that the loss function of neural network models is highly unfriendly. It not only has many local minimum traps but also requires gradient information to be obtained layer by layer. Therefore, training neural network models is a tricky problem in most cases. However, we also have many new ideas and methods in this regard. One of the revolutionary changes is the introduction of the ReLU activation function.
Sigmoid function:
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]
ReLU function:
\[ \text{ReLU}(x) = max(0,x) \]
We know that activation functions play a crucial role in introducing non-linearity. However, traditional activation functions, such as the sigmoid function (also known as the logistic function), are quite complex, which increases the difficulty of computing gradient information and even causes significant issues in the backward propagation of gradients. The introduction of the ReLU function has greatly addressed this problem.
Another point worth mentioning is batch learning. We know that algorithms (such as gradient-based methods) guide us toward the optimal model parameters using gradient information. Just like in statistics, where all data is used to update maximum likelihood estimates, traditional methods involve using all the data to compute the gradient information. However, this approach not only increases the computational load significantly but also hinders the learning process. Therefore, it was proposed that data could be fed to the model in random batches. In this way, the algorithm makes targeted adjustments based on a subset of the data each time, which greatly enriches the gradient information we can obtain.
The analogy that requires some imagination
For Chinese students, since there’s no English-speaking environment, the main method of learning English is through memorizing word lists. We often find ourselves holding a vocabulary list all day long. For those of us who don’t particularly enjoy learning languages, like me, it’s hard to stick to this method. As a result, we often start memorizing from A and quickly give up. This makes us Chinese students have a special kind of feeling toward the word “abandon”. 😊 But if we shuffle the order and use the “batch” method to memorize (e.g. reading a book) rather than holding the entire book, it might lead to better results.
Epochs and batch_size
Later on, when you use Keras, you will frequently encounter these two parameters. “Epochs” are like the number of times you change shoes when you’re shopping, while “batch_size” is the amount of data you feed to the model in each epoch, just like how you might try on a certain number of shoes each time you change. How to choose the batch_size? Well, people often choose powers of 2 as the batch size. he table below summarizes the key takeaways about choosing the batch size.
| Batch Size | Advantages | Disadvantages | Applicable Scenarios |
|---|---|---|---|
| Small Batch (16, 32, 64) | Stable training, reduces memory usage | Longer training time | Most tasks, default recommendation |
| Medium Batch (128, 256) | Balances speed and stability | May lead to local minima | When memory is sufficient |
| Large Batch (512+) | Faster training | Prone to local minima | When computational resources are abundant, very large datasets |
In addition to the Gradient Descent algorithm, we have many of its variant algorithms to choose from. In the next section, I will specifically discuss this point.
Challenge 3: Heavy computational works. Heavy computational tasks are something deep learning must face. Fortunately, we have more computing resources, so this is not a major issue. For example, we can use GPUs instead of CPUs for batch computations. I believe that, in the near future, we will have even more technologies to provide us with even greater computational power.
4.4 More options for shopping guides (Optimizers)
In recent years, with the rise of deep learning, many new optimization algorithms have been proposed. However, despite these variations, almost all of them are modifications of the Gradient Descent algorithm. These modifications typically focus on two main aspects: incorporating “Momentum” and more adaptive learning rate.
The concept of Momentum is not difficult to understand. Simply put, it involves using historical gradient information from the training process to adjust the current gradient information. The implementation of this idea is somewhat similar to autoregressive models, but we won’t show the specific formulas here. Another dimension of algorithm variation is a more adaptive learning rate. We want the optimizer to make large updates at the beginning, but become more gentle during finer stages. In other words, we need a learning rate that changes according to the amount of gradient information. The gradient descent algorithm modified with this idea are Adagrad (Adaptive Gradient) and Adadelta. When both Momentum and adaptive learning rate are considered together, we get the famous Adam (Adaptive Moment) algorithm.
Finally, I’ve summarized the commonly used optimization algorithms in Keras in the table below.
| Optimizer | Applicable Scenarios | Features |
|---|---|---|
| SGD | Suitable for small datasets, converges slowly but stable | Classic gradient descent, supports momentum and Nesterov |
| Adam | Suitable for most tasks, default choice | Automatically adjusts learning rate, fast, robust |
| Adagrad | Suitable for sparse data, tasks with fewer features | Adaptive learning rate, suitable for NLP |
| Adadelta | Similar to Adagrad, but avoids the issue of excessively small learning rates | Suitable for tasks with imbalanced gradients |
| AdamW | Adam + L2 regularization (weight decay) | Suitable for deep networks |
| Nadam | Adam + Nesterov momentum | Suitable for tasks requiring fast convergence |
In this section, we have discussed various aspects of deep learning. However, there is one important topic we haven’t addressed yet, which is model architecture. The design of the model architecture depends on the nature of our data. For example, for image data, we typically use Convolutional Neural Networks (CNNs); for sequential data, we usually use Recurrent Neural Network (RNN) architectures; and for text data, the most popular architecture currently is the famous Transformer. In the next section, we will provide a more detailed explanation of Convolutional Neural Networks.