2. The Road to Artificial Neural Networks
Textbooks typically introduce neural network models using fundamental Logical operation model. That approach is useful—I used to rely on it as well—but I’ve found that students often struggle with it. It can be challenging to grasp the essence of neural networks, let alone deep learning, in a clear and direct way. Here, my plan is to use Model Graphicalization along with PCA to lay the groundwork for understanding neural network models.
2.1 Model Graphicalization
Mathematicians always take a bird’s-eye view of the world, seeking out its most fundamental elements. The symbolic representation of a machine learning model is both concise and insightful, constantly reminding us of what truly matters. However, this notation is so minimalistic that it overlooks many details, while the earlier graphical representation is too cumbersome and impractical for expressing more complex models. Next, we introduce a more efficient graphical method.
2.2 Is PCA also a machine?
Of course, the answer is positive. If we understand PCA through the concept of image reconstruction, it is indeed a “machine” (a machine learning model). It is a transformation where the input consists of all the original variables, and the output is the reconstructed original variables. The specific performance of the model depends on all the PC weights.
That being the case, let’s now apply the graphical representation to this model.
Similar to the basic elements we discussed in the previous models, we also have inputs, outputs, hyperparameters, and model parameters here. Isn’t it fascinating? PCA can be seen as a very special kind of “machine.” Rather than focusing on its output, we are more interested in its internal byproducts—the principal components (PCs), \(\textbf{Z}\). This is mainly because our ultimate goal is to use the feature variables extracted by PCA to predict our predefined target variable. In other words, it is an intermediate step.
But do you remember the limitations of PCA that we mentioned in the first lecture? Yes, PCA is a linear feature extraction method, which means it has low flexibility. However, in complex problems, we often need more flexible nonlinear feature extraction methods to create new variables. So, can we improve PCA? Again, the answer is positive.
We are now very close to understanding neural network models and even deep learning models. However, we still need to clarify one concept: end-to-end learning.
2.3 Traditional Model vs New Age Model
Next, let’s discuss a broader question: the fundamental workflow to machine learning modeling. Yes, the process of building machine learning models follows a regular routine. However, deep learning marks a clear boundary where traditional and modern modeling approaches diverge significantly.
Simply put:
- Traditional modeling follows a two-step approach.
- Modern modeling, especially in deep learning, follows an end-to-end approach.
Let me explain in detail with the following slides.
So how can we implement this end-to-end approach in practice? Let’s return to a powerful nonlinear feature extraction model, the autoencoder.
Remark: It’s important to note that we usually include a constant term when calculating the score, similar to linear regression. However, for simplicity, we have omitted them in the figures.
This model indeed resembles a large network, but what’s its connection to neurons? Let’s check the figures below. On the far left of the figure is the simple model we discussed earlier. If we replace the input with the neurons from the previous layer and the output with new neurons, we obtain the basic unit of an ANN as shown in the middle. Doesn’t this basic unit look quite similar to a neuron in neuroscience?
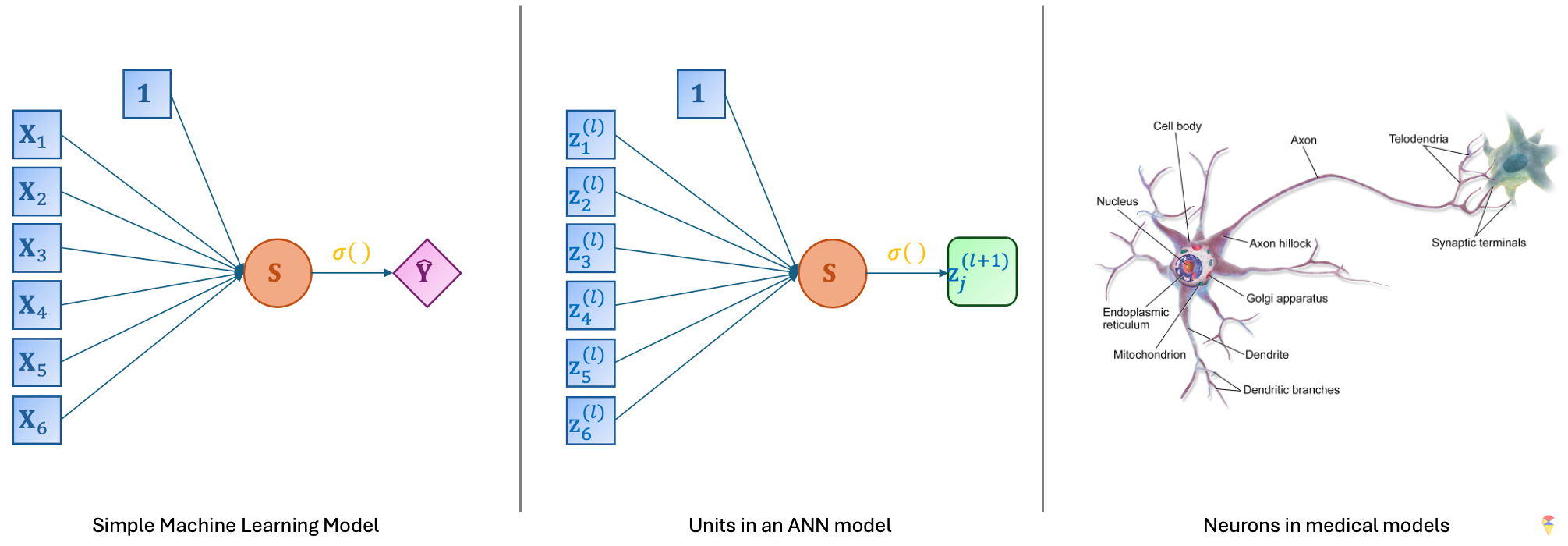
People in computer science are indeed great at naming things. Cool names like random forest, support vector machine, and so on pop up all the time in machine learning. However, just like how random forest has nothing to do with a real forest, ANN bears little resemblance to neurons in true neuroscience, both in terms of shape, scale, and working principles. ANN is just a cool name. However, there are scientists who are now researching the use of hardware to replicate real neurons. In my opinion, that could truly be the hopeful light for the future of artificial intelligence. Even with large language models being so popular right now, I still have to say this.
Quiz: Are linear regression models and logistic regression models considered special cases of neural network models?
2.4 On the top of Mount Tai

We have reached the destination of this journey. Just like standing upon Mount Tai, if you have understood the content above, then you have already grasped the fundamental principles of deep learning. Now, let’s take a closer look at our neural network model and name its elements.
Remark: There is one small note regarding the final layer: if our classification problem is a multi-class problem, say \(K\) classes, then we need to generate \(K\) score values from the previous layer. Also, we need to use the so called Soft-Max function as the activation function.
( NE )Soft-Max function is map from \(\mathcal{R}^K\) to \(K\) decimal numbers. Let \(\textbf{s} = (s_1,s_2,\dots,s_K)^{\top}\) as the \(K\) score values in the output layer. The \(k\)th output of Soft-Max function is \[ \sigma(\textbf{s})_k = \frac{e^{s_k}}{\sum_{k = 1}^K e^{s_k}} \]
Quiz:
- What is the range of \(\sigma(\textbf{s})_k\)?
- What is the relationship between logistic function and Soft-Max function?