Let me start with a motivating example. I have data on a guy’s height and weight: He is 170 cm tall and weigh 68 kg. Given that I know he is either Swedish or Chinese, which country do you think they are from? Do you have any ideas?
Let’s analyze this problem.
First, it’s clearly a classification problem—we want to make a judgment based on height and weight data.
Next, essentially, we now have an observation, so we can measure the likelihood value of this observation. However, if we want to measure the likelihood value, we first need to find an appropriate model.
This problem is simple; the bivariate normal distribution is definitely a fit, but we still need specific parameters to determine this normal model.
Returning to the problem itself: our premise is to make a judgment between Sweden and China. Clearly, we have two candidate models in front of us—the Swedish normal model and the Chinese normal model.
Now we have a plan. We can set up two candidate models and obtain their parameters from each country’s statistical department—that is, two means and a 2D covariance matrix. Then, we use these two models to evaluate the observed likelihood values for this person. If the likelihood value calculated from the Chinese model is higher than that from the Swedish model, we guess that they are Chinese; otherwise, we guess they are Swedish.
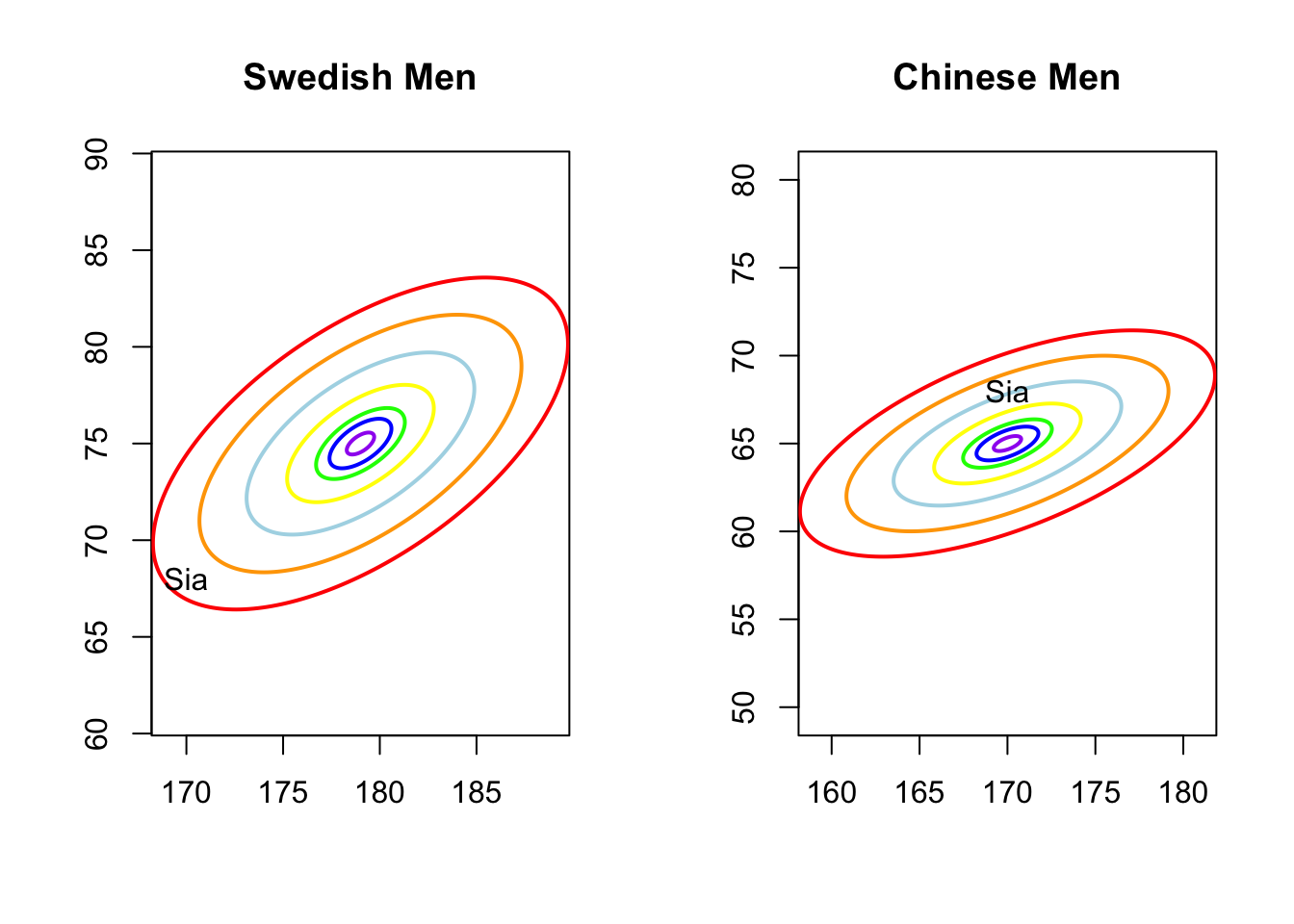
To do so, I got the statistics for both models, that is the average height and weight are \((179, 75)\), the SDs are \((5,4)\), and the correlation is \(0.6\) in Sweden; for China, the average values are \((170, 65)\), SDs are \((5.5,3)\), and correlation is also \(0.6\). Next, I plot the contour graphs of density function for both model and find the position of this guy in R
library(mvtnorm)library(ellipse)# my function for generating the contour mapcontour.g <-function(mu =c(0,0), Sigma, lwd=2, text =""){plot(0,0, xlim=c(mu[1]-2*sqrt(Sigma[1,1]),mu[1]+2*sqrt(Sigma[1,1])), ylim=c(mu[2]-1*sqrt(Sigma[2,2]),mu[2]+1*sqrt(Sigma[2,2])), asp =1,xlab ="", ylab ="", main = text) cv <-c(0.01,0.05,0.1,0.25,0.5,0.75,0.9) co <-c("purple","blue","green","yellow","light blue","orange", "red")for(i in1:7){points(ellipse(x = Sigma, centre = mu, level=cv[i], npoints=250), col=co[i], lwd=lwd, type ="l") }}# model Swedenmu1 =c(179, 75)sigma1 =matrix(c(5^2, 0.6*5*4, 0.6*5*4, 4^2), byrow = T, 2)# model Chinamu2 =c(170, 65)sigma2 =matrix(c(5.5^2, 0.6*5.5*3, 0.6*5.5*3, 3^2), byrow = T, 2)par(mfrow =c(1,2))contour.g(mu1, sigma1, text ="Swedish Men")text(x =170, y =68, "Sia" ) # find my positioncontour.g(mu2, sigma2, text ="Chinese Men")text(x =170, y =68, "Sia" ) # find my position
Oops, it was me. Obviously, under the Chinese model, I’m already a bit overweight but still within the light blue likelihood level, while under the Swedish model, I’m somewhat on the margins. So, the final judgment is that this guy is Chinese. As you know, I am originally from China, so our idea works. Great!
Disclaimer: Except for my personal data, all other data is fabricated purely for educational purposes, with no malice or discrimination intended.